Last updated on 18.1.2026
How to Download an Entire Website from the Archive's Wayback Machine?
Ever wondered how to retrieve an entire website from the Internet Archive’s Wayback Machine? This step-by-step guide will walk you through the process using a tool called the “Web Archive Downloader” (created by hartator). This Ruby-based application allows you to download complete websites from the web.archive.org.
Install Ruby
First, you need to install Ruby on your Windows. Make sure to choose the correct version according to your system’s architecture (32-bit or 64-bit).
Install Wayback_machine_downloader
Once Ruby is installed, you can install the Web Archive Downloader. To do this, navigate to the Start menu, find “Start Command Prompt with Ruby” and run it as an administrator. Then, enter the following command:
gem install wayback_machine_downloader_straw
This command will install the Wayback Machine Downloader on your PC.
Commands:
-d, --directory PATH
Specify the directory to store the downloaded files
By default, it’s ./websites/ followed by the domain name
Example:
wayback_machine_downloader http://domain.com --directory old_site/
-s, --all-timestamps
Retrieve all snapshots/timestamps for a particular website.
Example:
wayback_machine_downloader http://domain.com --all-timestamps
-f, --from TIMESTAMP
Limit to files on or after the provided timestamp (e.g., 20110616251441)
Example:
wayback_machine_downloader http://example.com --from 20110616251441
-t, --to TIMESTAMP
MY FAVORIT COMMAND
Limit to files on or before the provided timestamp (e.g., 20110616251441)
Example:
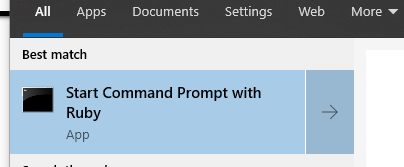
wayback_machine_downloader http://www.seo4starters.net --to 20100408142647
-e, --exact-url
Download only the specified URL, not the entire site
Example:
wayback_machine_downloader https://seo4starters.net/seo/ --exact-url
-o, --only ONLY_FILTER
Limit downloads to URLs that match this filter
(use // notation for the filter to be interpreted as a regex).
Examples:
If you’re interested in downloading files exclusively from a particular directory named “my_directory”, you can do that:
wayback_machine_downloader http://domain.com --only my_directory
Alternatively, if your goal is to exclusively download all image files and exclude all other types of content:
wayback_machine_downloader https://domain.com --only "/\.(jpg|gif|jpeg)$/i"
-x, --exclude EXCLUDE_FILTER
Avoid downloading URLs that match this filter (use // notation for the filter to be interpreted as a regex)
Example:
Suppose you aim to prevent the downloading of files within the directory named “my_directory.”
wayback_machine_downloader https://domain.com --exclude my_directory
If your intention is to download all files except for images:
wayback_machine_downloader https://domain.com --exclude "/\.(jpg|gif|jpeg)$/i"
-a, --all
Extend downloads to include error files (40x and 50x) and redirects (30x)
Example:
wayback_machine_downloader https://domain.com --all
-c, --concurrency NUMBER
Set the number of files to download simultaneously.
By default, it’s one file at a time (e.g., 20)
Example:
wayback_machine_downloader https://domain.com --concurrency 40
-p, --maximum-snapshot NUMBER
Set the maximum number of snapshot pages to consider (Default is 100)
Estimate an average of 150,000 snapshots per page
-l, --list
Only display file URLs in a JSON format with the archived timestamps, no downloads
The Process Explained
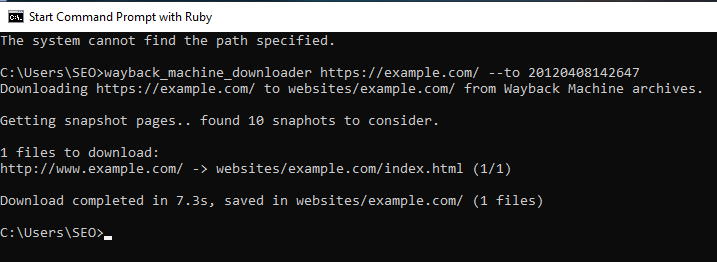
The tool operates by fetching the most recent iteration of each file available on the Wayback Machine and storing them in a directory named after the website, such as ./websites/domain.com/.
In addition, it reconstructs the original directory structure and automatically generates index.html pages, ensuring smooth compatibility with Apache and Nginx servers. The files retrieved are the original versions, not the versions rewritten by the Wayback Machine, thereby maintaining the original URL and link structures.
How to use on linux?
To utilize the Wayback Machine downloader on your Mac, there’s no requirement for a ruby installation. Simply start your Terminal and input the following command:
gem install wayback_machine_downloader
For those using EL Capitan or newer versions of the operating system:
sudo gem install wayback_machine_downloader -n/your_usr/local/bin
After executing the above command, the Wayback Machine downloader will be set up on your system. Subsequently, you’ll be able to download websites using specific commands, just like on Windows.