עודכן לאחרונה ב-9.7.2024
אחרי שהוסיפו ל-ChatGPT את הגישה לאינטרנט (בבאטא) וכשקראתי שיש לו user-agent משלו, נפל לי האסימון שהבוטים הזוחלים שלו הם כמו הבוטים הזוחלים של שאר מנועי החיפוש ותוכנות סריקה כמו sitebulb או screaming frog שגם להן יש user-agent משלהן.
אז החלטתי לבדוק אם ניתן לראות דרך הצ’אט את אופן הפעולה וההתנהגות של הבוטים הזחלנים – והתשובה היא שכן.
אז איך בדקתי את זה?
בגלל שכרגע הצ’אט משתמש בפלאגינים שהם סוג של תוספי עזר חיצוניים המסייעים לו לקרוא את העמודים, החלטתי לא להשתמש בהם אלא להביא לו קוד/קובץ HTML נקי של עמוד מסוים עם שימוש בפונקציה החדשה שלו: “Code interpreter”.
(העתקתי את כל הקוד המלא שבמקור הדף של העמוד לתוך קובץ טקסט והגשתי לו).
בלחיצה על ה”show work” אפשר ממש לראות את הפעולות שהזחלן מבצע בשביל לקרוא ולהבין את העמוד – שזה למעשה אנלוג הפעולות הבסיסיות של כל זחלן אחר.
תמיד ידעתי שצריך שהקוד של האתר צריך להיות כמה שיותר נקי בשביל שלזחלן של גוגל יהיה קל יותר לקרוא אותו, אבל אף פעם לא ראיתי את הפעולה שלו באופן מעשי, וה-ChatGPT עכשיו מגלה את כל הסודות.
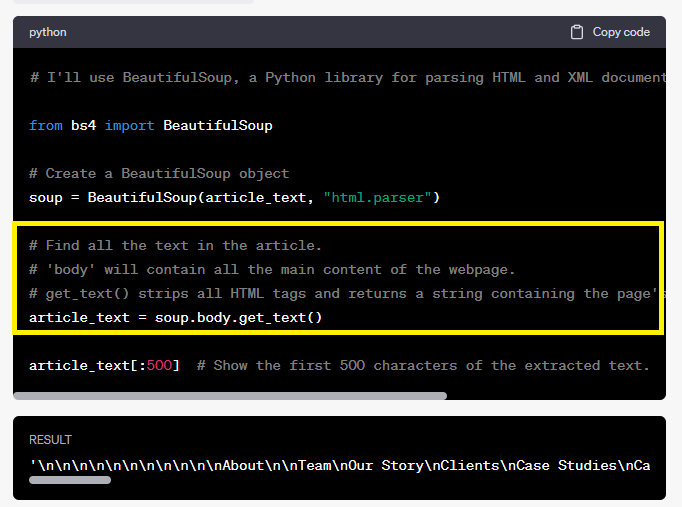
הוא מסביר שהמטרה שלו היא למצוא את כל התוכן שבעמוד
הוא יודע שהתוכן צריך להיות ב-body (ראיתי לא מזמן באתר מתחתנים שיש בו פעמיים תגית body, ועכשיו אני מבין עד כמה זה חמור…)
לאחר מכן הוא מסביר את הפעולה שהוא עושה למשיכת הקוד
ובתוצאה הוא מציג את התוצאה שהוא מצא למטה, שזה התפריט – ובגלל שיש תגית nav הוא מבין שזה התפריט ולא התוכן העיקרי
*הצ’אט מוגבל בביצועים שלו לכן הוא יכול לקרוא רק 500 תווים כל פעם, למנועי חיפוש אחרים זה פשוט יותר בקטע הזה בגלל שיש להם יותר משאבים.
לאחר מכן באותה התשובה הוא אמר לי שהוא מבין שזה התפריט – הוא ממשיך לחפש את התוכן הבא ואומר שבשביל לבצע את זה הוא יחפש את תגיות ה-HTML שנוהגות להכין בתוכן את התוכן שהן:
- <section>
- <article>
- <div>
- <p>
ואלו הן פקודות הקוד שהוא מבצע על מנת לאתר את התוכן:
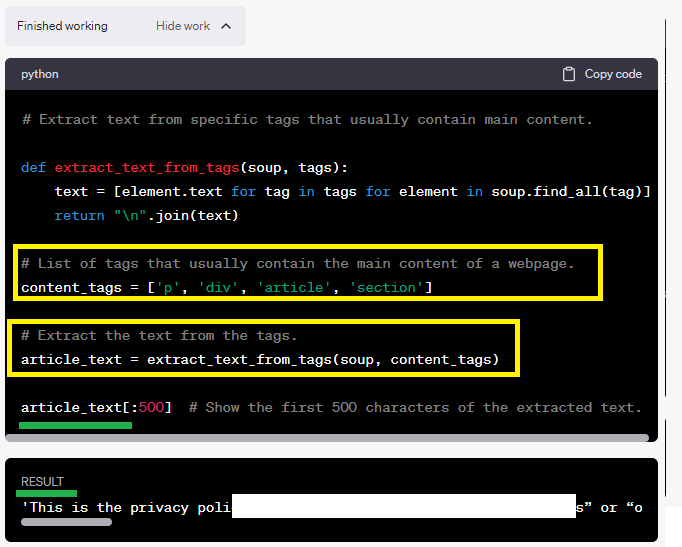
בתשובה לאחר מכן הוא רשם לי את התוכן שהוא מצא (500 התווים הראשונים, בגלל המגבלה שלו)
אך בגלל שבאתר יש קוד תקין, הוא כבר איתר באופן מדויק את המאמר, וכל פעם שאני מבקש ממנו להמשיך הוא מייצא לי את ה-500 תווים הבאים של המאמר (ללא פונקציות חיפוש נוספות).
בדוגמה שהצגתי רואים עד כמה קל לזחלן למצוא ולקרוא את התוכן העיקרי של העמוד בזכות שימוש בתגיות HTML תקינות וקוד מסודר (לא עמוס מידי).
מקרה אחר - קריאת אתר עם קוד לא תקין
עכשיו אראה דוגמה נוספת עם קוד של אתר אחר שהגשתי לו (אתר ישראלי) על מנת לראות עד כמה טוב הזחלן מצליח לקרוא את העמוד ולהגיע לתוכן העיקרי (לצערי התוצאה לא הייתה אופטימית..).
אז לאחר הגשת הקוד באותו האופן ובקשה לייצא את התוכן העיקרי של העמוד, הוא מתחיל את העבודה באותה בצורה כמו במקרה הקודם:
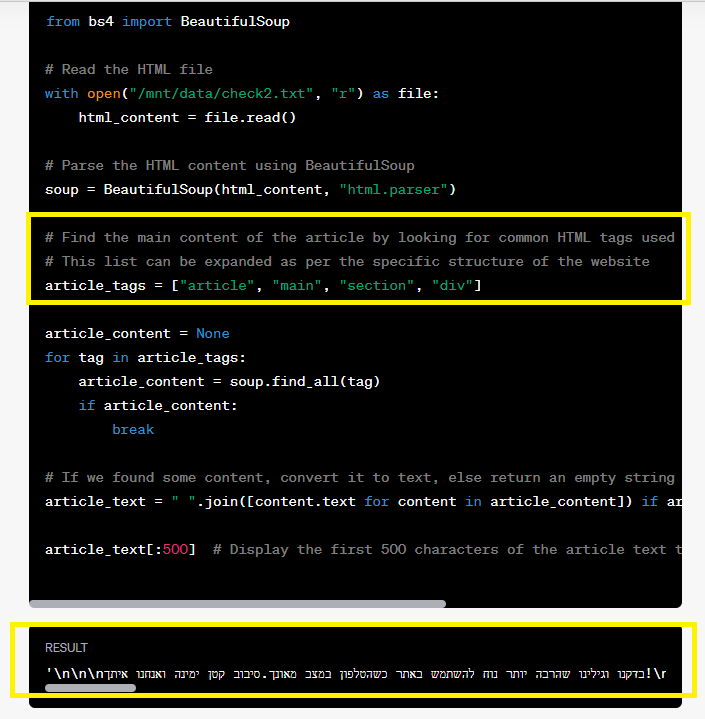
התוצאה שהוא מצא – זה תוכן תחת תגית של תפריט, אבל התוכן שבפנים לא קיים בכלל באתר, ניתן לראות אותו רק בקוד: “בדקנו וגילינו שהרבה יותר נוח להשתמש באתר כשהטלפון במצב מאונך.סיבוב קטן ימינה ואנחנו איתך…”.
למה שכתוב אין בכלל קשר למה שמופיע בתפריט האתר…
לאחר מכן הוא מבין שהתוכן בעברית ומציע לי לתרגם:
“The article appears to be in Hebrew. Let me translate it into English to better understand its content”
ובסופו של דבר הוא מציג לי שגיאה:
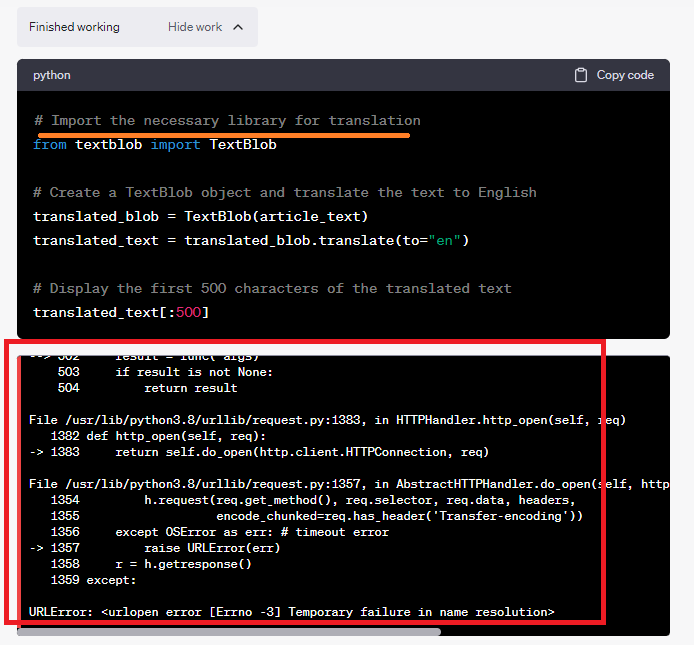
הוא מתנצל על כך ואומר שלא הצליח לקרוא את הקוד.
לאחר כמה בקשות נוספות, הוא מנסה שיטות אחרות אך עדיין לא מצליח להגיע לתוכן העיקרי:
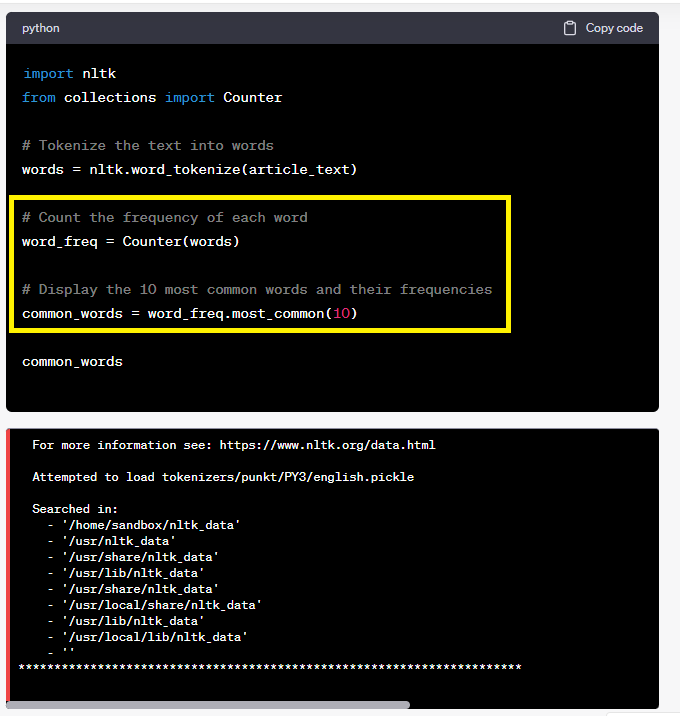
מה שמעניין פה – זה שעל מנת לאתר את התוכן העיקרי הזלחן מפעיל פונקציית חיפוש שסופרת את תדירות המילים שבעמוד.
*נקודה למחשבה – כנראה בשביל להבין על מה המאמר מדבר, העמוד עדיין צריך שלמילת המפתח תהיה את התדירות הגבוהה ביותר (אפילו שזה נשמע קצת פרימיטיבי וקצת נוגד את ההנחיות של גוגל).
אבל עדיין, למרות זאת הוא לא מצליח להגיע לתוכן העיקרי.
לאחר שהוא מתנצל, הוא מבקש ממני לתאר לו את המאמר או לתת לו “רמז” – של איזה ביטוי לחפש
אני רושם לו את הביטוי שהוא צריך לחפש בתוכן – “תחפש את המילה: X משם מתחיל המאמר”
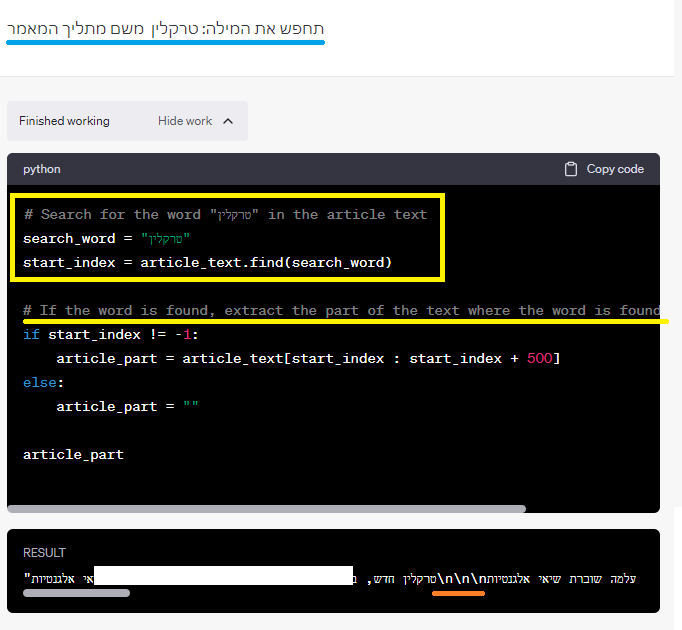
ובתמונה ניתן לראות שרק לאחר שכיוונתי אותו הוא מפעיל פונקציית חיפוש שעוזרת לו לאתר את המילה, הוא מקשיב “לרמז” שנתתי לו – המילה שאחריה מתחיל המאמר.
ובתוצאה הוא מייצא לי את המאמר, משום מה הוא קולט שיש תגית של תפריט בפנים – דבר נוסף שמעיד שהקוד מלוכלך.
כמובן שיש לקחת את זה בערבון מוגבל בגלל שהזחלנים של גוגל והמנועים האחרים יותר מתקדמים וכנראה שהם כן מצליחים להגיע לתוכן יותר בקלות אבל עדיין אני מאמין שזה דורש מהם הרבה יותר משאבים.
המסקנות שלי מהניסוי
- מאוד חשוב לשמור על קוד נקי באתר – רואים את הקושי של הזלחן לאתר את התוכן במקרה שהקוד לא תקין.
- חשוב להקפיד על תגיות HTML תקינות – זה משהו שמאוד עוזר לזחלן להגיע לתוכן.
- יש להתחשב בתדירות מילת המפתח העיקרית או לפחות בהופעה שלה.
- זאת בדיקה מעולה לבצע על כל אתר בשביל לראות אם הזחלנים מצליחים להגיע לתוכן בקלות והאם הקוד הוא נקי.
מאמרים קשורים: